
- 추가적인 가상메모리를 런타임에 획득할 필요가 있을 때 동적 메모리 할당을 사용한다.
- 편리성, 호환성
Intro. 동적 메모리 할당
malloc, garbage collector

- 힙(heap)을 관리한다.
- 프로세스의 가상메모리 영역
- 초기화되지않은 데이터 영역 직후에 시작해서 위쪽(낮은 주소에서 높은 주소로) 커지는 메모리 영역
- 각각의 프로세스에 대해서 커널은 힙의 꼭대기를 가리키는 변수
brk(break)를 사용한다. - 힙을 다양한 크기의 블록들의 집합으로 관리한다.
- 각 블록은 할당 or 가용한 가상메모리의 연속적인 묶음이다.
< 할당 🆚 가용 >
- 할당된 블록 : 응용하기 위해 명시적으로 보존된다.
- Ex. C의 malloc으로 동적 메모리가 할당된 상태
- 할당된 블록은 메모리 할당기에 자신에 의해 ‘명시적(malloc)’ 또는 ‘묵시적(가비지 컬렉션)’으로 반환될 때까지 할당된 채로 남아있다.
- 가용한 블록 : 할당을 위해 사용할 수 있다.
- Ex. C의 free으로 동적 메모리가 해제된 상태 or 아직 메모리가 한번도 할당되지 않은 상태
< 명시적 할당기 🆚 묵시적 할당기 >
- 명시적 할당기(Explicit allocators)
- 명시적으로 할당된 블록을 반환해줄 것을 요구한다.
- Ex 1. C : malloc 호출로 블록 할당 ↔ free 호출로 블록 반환
- Ex 2. C++ : new 호출로 블록 할당 ↔ delete 호출로 블록 반환
- 묵시적 할당기(Implicit allocators)
- 할당된 블록이 언제 더 이상 프로그램에서 사용되지 않고 블록을 반환하는지 탐지한다.
- 묵시적 할당기 : 가비지 컬렉터(garbage collector)
- 묵시적 할당 작업 : 가비지 컬렉션(garbage collection)
9.9.1 malloc, free
- C에서는
malloc함수를 호출해서 힙으로부터 블록들을 할당받는다.
🌟 워드(words) : 4바이트 객체
🌟 더블 워드(double words) : 8바이트 객체
malloc

- 어떤 종류의 데이터 객체에 대해서 적절히 정렬된 최소
size바이트를 갖는 메모리 블록의 포인터 리턴한다.
- 실제 구현에서 메모리 블럭의 정렬
- 32비트 모드(
gcc -m32) : 항상 8의 배수로 블록 리턴 - 64비트 모드(
gcc 기본설정) : 항상 16의 배수로 블록 리턴
- 32비트 모드(
- 프로그램이 가용할 가상메모리보다 더 큰 크기의 메모리 블록을 요청하는 경우에는 NULL을 리턴하고, errno를 설정한다.
💡 errno ?
variable errno is set by system calls and some library functions in the event of an error to indicate what went wrong.
_ errno(3) - Linux manual page- 오류 발생 시 시스템 호출 및 일부 라이브러리 함수에 의해 설정되어 무엇이 잘못되었는지 나타낸다.
- 에러를 나타내는 전처리기 매크로이며 보통 표준 라이브러리에서 많이 사용한다.
malloc은 리턴하는 메모리를 초기화하지 않는다.calloc: 할당된 메모리를 0으로 초기화realloc: 이전에 할당된 블록의 크기를 변경
- → 기본적으로 dummy 값들이 들어있으며 초기화를 원하는 경우에는
calloc을 사용할 수 있다.
- malloc의 명시적 힙 메모리 할당 및 반환
mmap과munmap함수 사용sbrk함수 사용
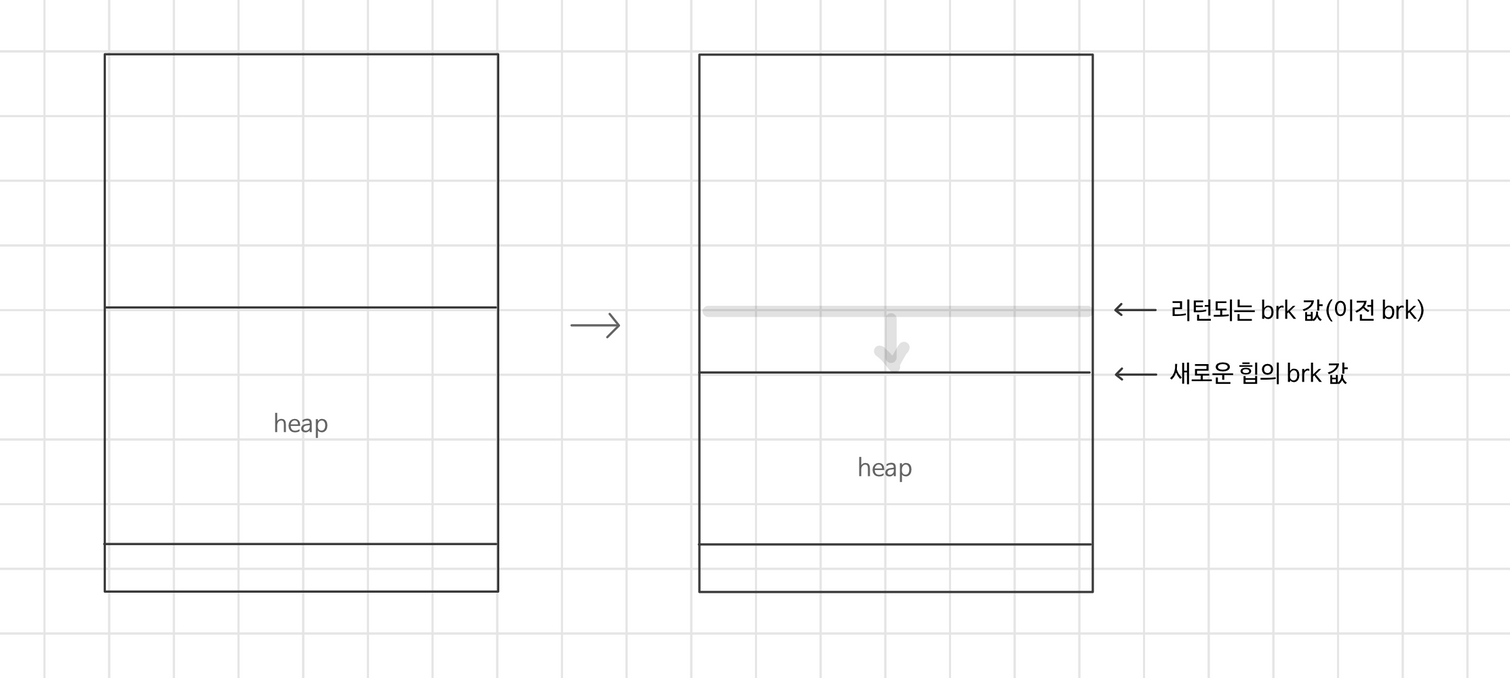
sbrk

- 커널의
brk포인터에incr를 더해서 힙을 늘이거나 줄인다.- 성공 시, 이전
brk값을 반환 - 실패 시, -1 리턴 및 errno = ENOMEM 설정
- 성공 시, 이전
ENOMEM : Not enough space/cannot allocate memory (POSIX.1-2001).
_ errno(3) - Linux manual pageincr를 음수로 설정하는 건 유효하지만 리턴 값이 새로운 힙의 탑보다 abs(incr) 높은 위치에 있어서 복잡해진다.
incr을 음수로 설정했을 때
free

- 프로그램은 할당된 힙 블록을
free를 사용해서 반환한다. ptr은 할당된 블록의 시작 위치를 가리킨다.
free는 아무것도 리턴하지 않기 때문에 애플리케이션에게 메모리 상의 오류를 알릴 방법이 없다.
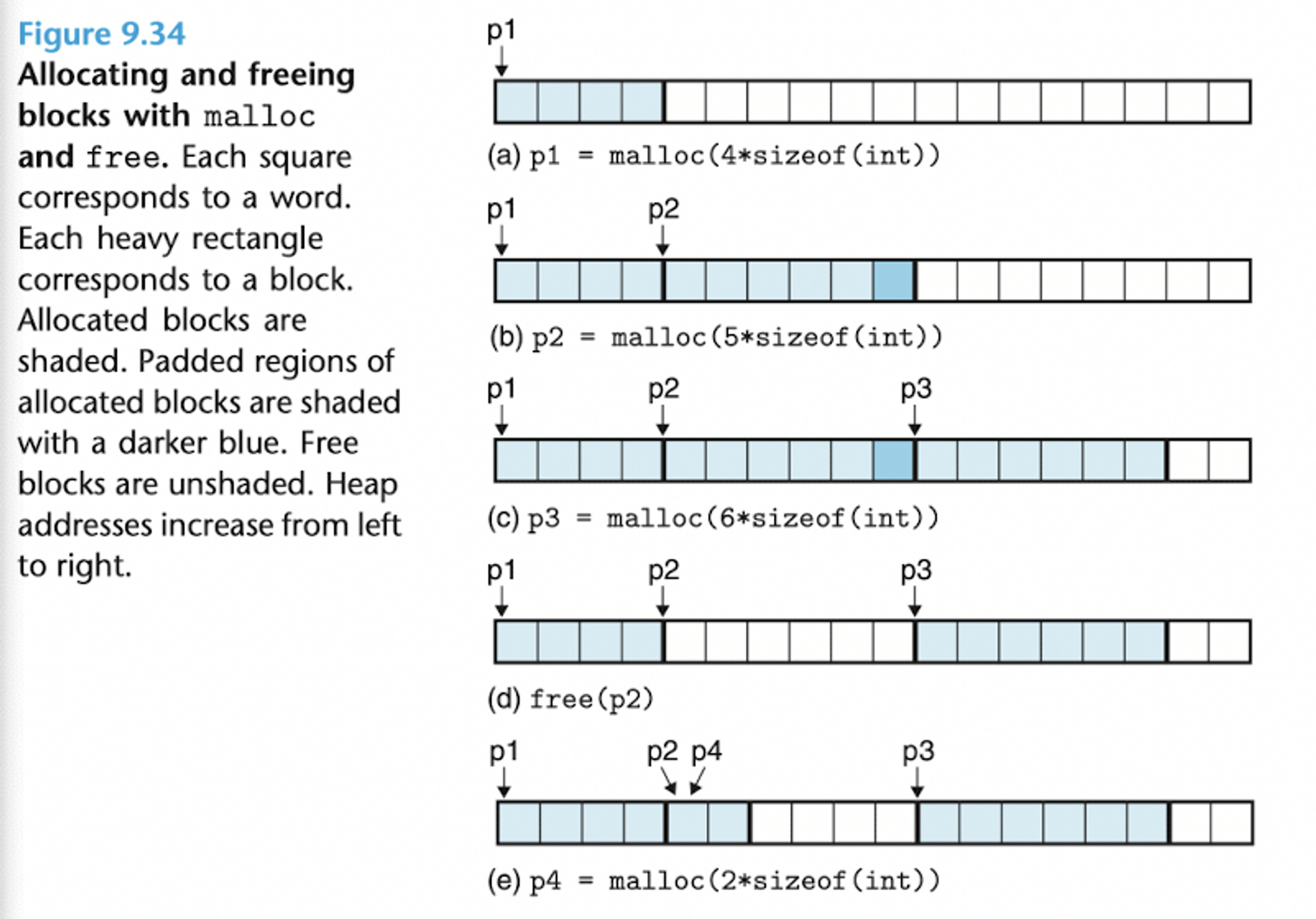
- (초기 상태) → 힙 : 18 워드 크기로 구성, 더블 워드 (8byte) 정렬
- (a) → 4워드 블록 요청에 따라 가용 블록 앞부분에서 4워드 블록 할당, 첫 번째 워드 포인터 리턴
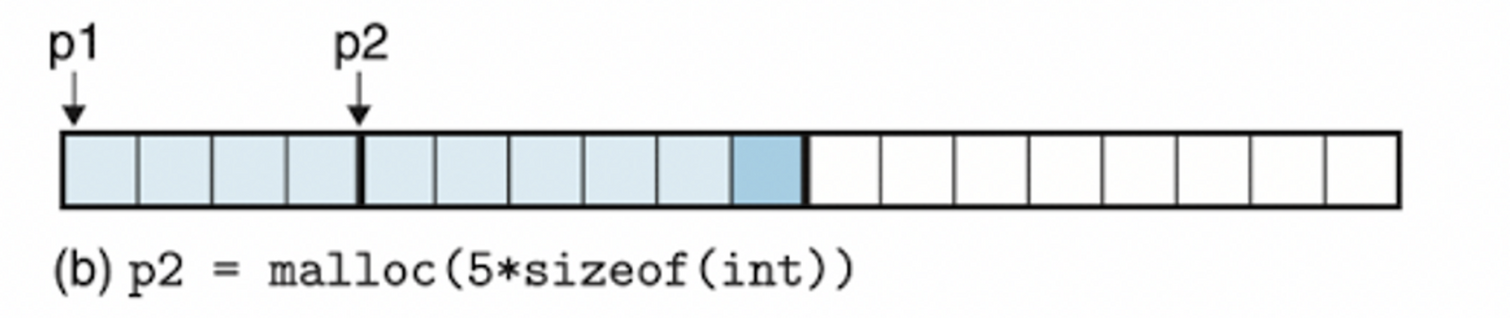
- (b) → 5워드 블록 요청에 따라 가용 블록 앞부분에서 6워드 블록 할당
- 이때 더블 워드 정렬을 맞추기 위해 기존 요청에 따른 5워드에 1워드 패딩을 추가했다.
- (c) → 6워드 블록 요청에 따라 가용 블록 앞부분에서 6워드 블록 할당
- (d) → (b)에서 할당된 6워드 블록 반환
- ⚠️ p2 포인터는 여전히 해제된 위치를 가리키고 있다.
- (e) → 2워드 블록 요청에 따라 가용 블록 앞부분(이전에 반환된 블록 부분)에서 2워드 블록 할당
9.9.2 Why Dynamic Memory Allocation?
- Reason - 프로그램을 실제 실행시키기 전에는 자료 구조의 크기를 알 수없는 경우들이 있기 때문이다.
↔ 정적 메모리 할당 : 프로그램이 실행되기 이전에 이미 사용할 데이터에 대한 크기가 확정되어 있다.
- 이때의 유일한 대책은 사용할 데이터의 크기를 확장한 뒤 다시 컴파일한다.
- 반면에 런타임 시에 동적으로 메모리를 할당한다면 사용할 데이터의 크기는 사용가능한 가상 메모리의 양에 의해서만 제한된다.
9.9.3 Allocator Requirements and Goals
- 명시적 할당기의 제한 사항
- Handling arbitrary request sequences
- 애플리케이션은 할당과 반환 요청에 있어서 일정한 순서를 갖는다는 보장이 어렵다.
- Making immediate responses to request.
- 어떤 종류의 데이터 객체라도 저장할 수 있도록 하는 방식으로 정렬해야한다.(void)
- Using only the heap.
- 확장성을 위해 힙 자체에 자료 구조들은 힙 자체에 저장되어야 한다.
- Aligning blocks.
- 데이터 객체가 어떤 종류더라도 저장할 수 있도록 하는 방식으로 정렬해야한다.
- Not modifying allocated blocks.
- 가용 블럭에 대해서만 조작하거나 변경할 수 있다.
- Handling arbitrary request sequences
- 목표 1. 처리량 최대화
- 처리량 : 단위 시간당 완료되는 요청의 수
- Ex. 1초 동안 500개의 할당 요청과 500개의 반환 요청 수행 → 초당 1,000 연산
- 할당과 반환 요청들을 만족시키기 위한 평균 시간을 최소화해서 처리량을 최대화한다.
- 목표 2. 메모리 이용도 최대화
- 가상메모리는 무한 자원이 아니다.
- 한 시스템에서 모든 프로세스에 의해 할당된 가상메모리의 양은 디스크 내의 swap space에 의해 제한된다.최고 이용도(peak utilization)를 사용해서 할당기가 힙을 얼마나 효율적으로 사용하는지 규정한다.
- 💡 스왑 공간 (Swap space) : 리눅스에서 물리적 메모리 (RAM)의 용량이 가득 차게될 경우 사용되는 여유 공간
- 최고 이용도(peek utilization)
- 애플리케이션에 p 바이트 블록 요청
- 요청 : $R_k$
- 현재 할당된 블록들의 데이터들의 합 : $P_k$
- 힙의 크기 : $H_k$
- 첫 번째 $k$ 요청에 대한 최고 이용도 : $U_k$
U_k = \frac {max_{i <= k}\quad P_i} {H_k}
$$
- 할당기의 목적 : 최고 이용도를 전체 배열에 대해서 최대화한다.
9.9.4 Fragmentation
- 단편화(Fragmentation) : 가용 메모리가 할당 요청을 만족시키기에는 가용하지 않았을 때 발생(가용 블록이 충분하지 않은 상태)
- 내부 단편화(Internal fragmentation)
- 외부 단편화(external fragmentation)
- 내부 단편화(Internal fragmentation)
- 할당된 블록이 데이터 자체보다 더 클 때 발생한다.
- 내부 단편화의 양은 이전에 요청한 패턴과 할당기 구현에만 의존한다.
- Ex. (b)에서 할당 요청 데이터의 크기는 5워드이지만 더블 워드 정렬 조건을 만족하기 위해 할당된 블록의 크기는 6워드이다.
- 이때,
(할당된 블록의 크기) - (요청 데이터의 크기) = 1이므로 1byte 의 내부 단편화가 발생했다.

- 외부 단편화(external fragmentation)
- 전체적으로 공간을 모았을 때는 요청을 처리할 수 있는 충분한 크기가 존재하지만, 이 요청을 처리할 수 있는 단일한 가용블록 자체는 없는 경우에 발생한다.
- Ex. 만약 (e) 요청에 2워드가 아니라 8워드였다면 힙에 있는 전체 가용 워드를 모았을 때는 가능하지만 8워드를 만족하는 블록은 없으므로 만족시킬 수 없다.
- 외부 단편화 🆚 내부 단편화
- 내부 단편화 : 이전 요청의 패턴과 할당기 구현에 의존
- 외부 단편화 : 이전 요청의 패턴과 할당기 구현에 의존 + 미래의 요청 패턴에도 의존
- Ex. 일정 시점에 모든 가용 블록들이 4워드의 크기를 가질 때, 이후의 요청에 대해서 4워드보다 큰 블록에 대한 요청이 들어오면 외부 단편화가 발생한다.
- → 미래의 요청 패턴에 외부 단편화의 발생 여부가 결정된다.
9.9.5 Implementation Issues
- 단순히 스택을 사용하여 선형적으로 구현하는 방법
1. 힙을 하나의 커다란 바이트 배열로 생각한다.
2. 이 배열의 첫 번째 바이트를 가리키는 포인터 p(실제 힙에서는 brk)가 있다고 한다.
3. size 바이트를 할당하기 위해서 malloc은 현재 p 값을 스택에 저장하고 p를 size 크기만큼 증가시키고, p의 이전 값을 리턴한다.
4. free는 아무것도 하지않고 리턴한다.
- 이러한 방식으로 할당기를 구현하면 malloc과 free가 적은 수의 인스트럭션을 처리하므로 처리량은 매우 좋다.
- But, 블록들을 재사용하지 않으므로 메모리 이용도는 매우 나쁘다.
- 할당기 구현에 있어서 고려해야할 이슈들
- Free block organization : 어떻게 가용 블록을 지속적으로 추가하는가
- Placement : 새로 할당된 블록을 배치하기 위한 가용 블록을 어떻게 선택하는가
- Splitting : 새로 할당한 블록을 가용 블록에 배치한 후 가용 블록의 나머지 부분들로 무엇을 하는가
- Coalescing : 방금 반환된 블록으로 무엇을 할 것인가
9.9.6 Implicit Free Lists
- 할당기 구현에 있어서 필요요소
- 블록 경계를 구분한다.
- 할당된 블록과 가용 블록을 구분하는 데이터 구조를 필요로 한다.
- 이러한 정보를 블록 내에 내장한다.
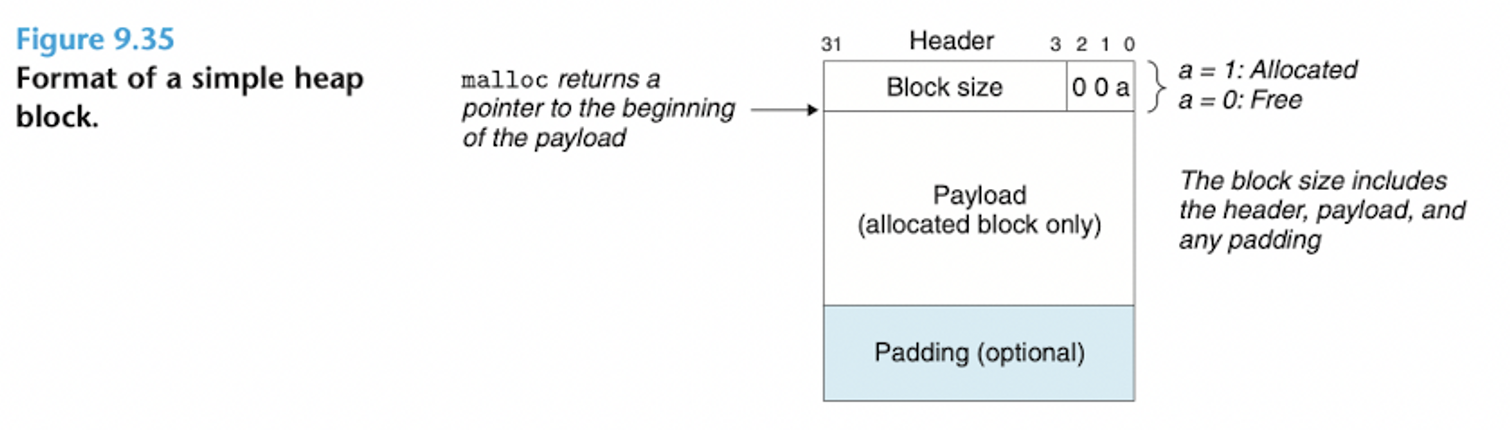
(힙 블록 하나의 포맷)
- 한 블록은 헤더(Header), 데이터(Payload), 추가 패딩(Padding)으로 구성된다.
- 헤더(Header)
- 블록 크기(헤더 ~ 패딩까지 포함)
- 하위 3비트는 항상 0이며 다른 정보를 인코드하기 위해 남겨둔다.
- 하위 3비트에 최소 중요 비트(할당된 비트)도 포함된다.
- 최소 중요 비트 : 해당 가용 상태(블록의 할당 여부)를 나타낸다.
- → 위의 그림에서 뒤의 3비트에서 a자리에 해당한다.
- 헤더는 1워드(4byte = 32bit)이다.
- 블록 크기(헤더 ~ 패딩까지 포함)
- 데이터(Payload)
- 애플리케이션이
malloc을 불렀을 때 요청한 데이터가 따라온다.
- 애플리케이션이
- 패딩(Padding)
- 패딩의 크기는 가변적이다.
- 패딩을 해야하는 이유
-
- 외부 단편화를 극복하기 위한 전략
- 정렬 요구사항을 만족하기 위해
-

- 블록 포맷의 연속된 형태로 묵시적 가용리스트로 힙을 표현할 수 있다.
- 묵시적 가용 리스트의 블록 하나가 위의 블록 포맷 하나를 나타낸다.(1워드 = 4byte = 32bit)
- 가용 블록이 헤더 내 필드에 의해 묵시적으로 연결된다.
∴ 할당기는 간접적으로 가용 블록 전체 집합을 힙 내의 전체 블록을 다니면서 방문할 수 있다.
- 묵시적 가용 리스트에서는 마지막 블록이 필요하다.
- 해당 블록은 ‘종료하는 헤더(terminating header)’로 할당 비트가 세팅되어 있고 크기는 0을 갖는다.
- 할당 비트를 세팅하면 가용 블록들의 연결이 단순해진다.
❓ 힙의 첫 블록은 사용하지 않는 블록으로, 전체 힙의 패딩을 맞추기 위해 사용한다.
Ex. 힙에 “더블 워드 정렬 제한 조건”을 적용 시
- 블록 크기 : 항상 8의 배수(8byte)
- 처음 1워드는 무조건 헤더이다.
- 그러면 2워드부터 데이터를 넣을 수 있다.
💡 실제 malloc 에서 메모리 블럭의 정렬 (Ch 9.9.1 참조)
- 32비트 모드(
gcc -m32) : 항상 8의 배수로 블록 리턴 - 64비트 모드(
gcc 기본설정) : 항상 16의 배수로 블록 리턴
- 묵시적 가용 리스트의 장단점
- 장점 : 단순하다.
- 단점 : 가용 리스트를 탐색해야하는 연산들의 비용이 힙에 있는 전체 할당 블록과 가용 블록의 수에 비례한다.
9.9.7 Placing Allocated Blocks
애플리케이션이 k바이트의 블록을 요청할 때 할당기는 요청한 블록을 저장하기에 충분히 큰 가용 블록을 리스트에서 검색한다.
검색 수행 방법(배치 정책)
- First fit
p = start;
while ((p < end) && \\ not passed end
((*p & 1) || \\ already allocated
(*p <= len))) \\ too small
p = p + (*p & -2); \\ goto next block (word addressed)- 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택한다.
- 전체 블록에 대한 선형시간이 소요된다.
- 리스트의 앞 부분에 작은 가용 블록들을 남겨둔다.
- Next fit
- First fit과 유사하지만 검색 시작 지점이 다르다.
- 이전에 검색이 종료된 지점에서부터 검색을 시작한다.
- 불필요한 재탐색을 방지할 수 있어서 ‘First fit’ 방법보다 수행 속도가 빠르다.
- 단편화에 있어서 최악이다.
- 💡 ”이전 검색에서 가용 블록을 발견했다면 다음 검색에서는 리스트의 나머지 부분에서 원하는 블록을 찾을 가능성이 높다” 는 아이디어에서 출발
- Best fit
- 모든 가용 블록을 검사하며 가장 적은 바이트 수가 낭비되는 크기가 맞는 블록을 선택한다.
- 단편화가 적게 발생하고 대개 메모리 이용률을 개선시킨다.
- 보통 ‘First fit’ 보다 느리다.
- 메모리 : Best fit < First fit < Next fit
- 시간 : Next < First < Best
9.9.8 Splitting Free Blocks
할당기가 크기가 맞는 가용 블록을 찾은 후에 가용 블록의 어느 정도를 할당할 지에 정책적 결정을 내려야한다.
- 가용 블록의 어느 정도를 할당할 것인가
- 가용 블록 전체를 사용하는 방법 : 간단하고 빠르지만 내부 단편화가 발생한다.
- 개선 방법 : 가용 블록을 두 부분으로 나눈다.
- 할당한 블록
- 새로운 가용 블록
9.9.9 Getting Additional Heap Memory
- 할당기가 요청한 블록을 찾을 수 없는 경우
- 메모리에서 물리적으로 인접한 가용 블록을 연결해서 더 큰 가용 블록을 만들어본다.
- 커널에게
sork함수를 호출해서 추가적인 힙 메모리를 요청한다.- 추가 메모리를 한 개의 더 큰 가용 블록으로 변환한다.
- 해당 블록을 가용 리스트에 삽입한다.
9.9.10 Coalescing Free Blocks
- 할당한 블록을 반환할 때, 인접한 다른 가용 블록들이 있을 수 있다.
→ 인접 가용 블록으로 부터 오류 단편화(false fragmentation)가 발생할 수 있다.
오류 단편화(false fragmentation)
- 사용할 수 없는 가용 블록으로 쪼개진 많은 가용 블록이 존재한다.
- 인접 가용 블록들을 연결하면 큰 메모리 요청을 처리할 수 있으나, 메모리가 쪼개져 있어서 해당 요청을 처리할 수 없는 경우를 말한다.
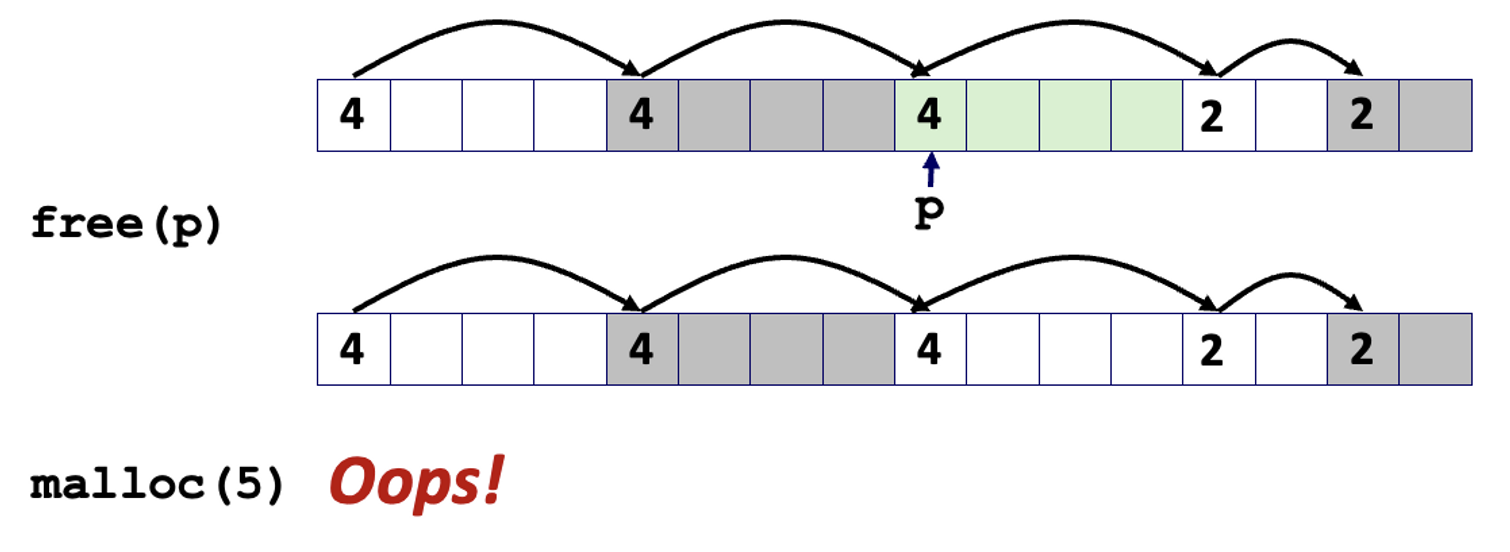
- p에 대한 메모리 공간을 반환한다.
- 이후 5워드의 메모리 공간을 요청한다.
- 4워드 크기의 가용 블록과 2워드 크기의 가용 블록으로 쪼개져 있어서 5워드 크기의 메모리 공간을 할당할 수 없다.
- → 💥 오류 단편화(false fragmentation) 발생
- 오류 단편화를 극복하기 위한 방법 : 연결(Coalescing)
- 연결 : 인접 가용 블록들을 통합한다.
- 언제 연결을 수행해야하는가?
- 즉시 연결(Immediate coalescing)
- 블록이 반환될 때마다 인접 블록을 통합한다.
- 간단하며 상수 시간 내에 수행할 수 있다.
- 불필요한 분할과 연결을 유발할 수 있다.
- 지연 연결(Deferred coalescing)
- 일정 시간 후에 가용 블록들을 연결하기 위해 기다린다.
- 💡 빠른 할당기들은 종종 지연 연결의 형태를 선택한다.
- 즉시 연결(Immediate coalescing)
9.9.11 Coalescing with Boundary Tags
- 다음 가용 블록을 연결하는 방법
- 현재 블록을 “current block”이라 한다.
- 현재 블록의 헤더로 부터 다음 블록의 위치를 알 수 있다.
→ 다음 블록의 위치를 알면 헤더를 알 수 있고 ‘allocated bit’로 부터 다음 블록이 가용 블록인지 할당 블록인지 알 수 있다.
→ 현재 위치에서 헤더에 있는 블록 사이즈를 더하면 다음 블록의 위치를 알 수 있다.
- 이전 가용 블록을 연결하는 방법
- “경계 태그”를 사용한다.
경계 태그(Boundary tags)
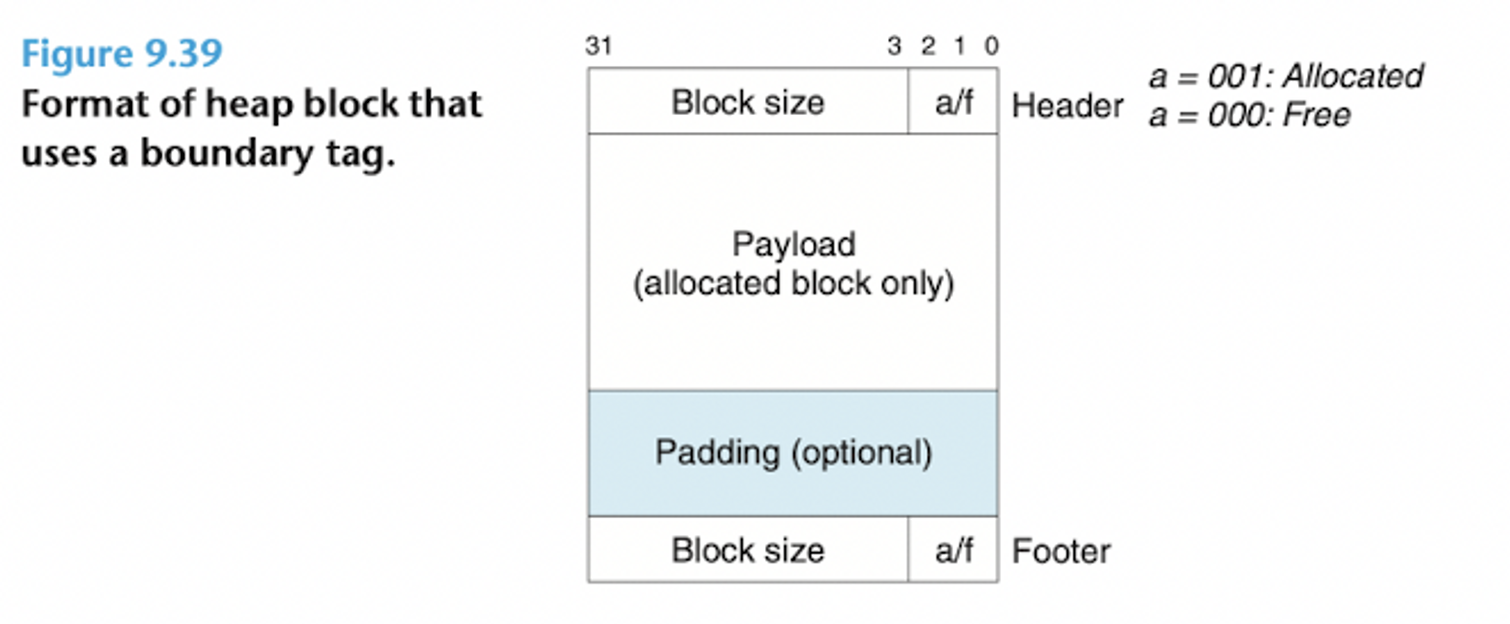
- 각 부분의 끝 부분에 footer(경계 태그)를 추가한다.
- footer : 헤더를 복사하여 만들 수 있다.

- 각 블록이 경계 태그를 사용하는 포맷으로 구성되어있다면 블록을 연속적으로 이어붙인 형태로 표현하면 위와 같은 형태가 나온다.
- 블록의 시작 위치와 이전 블록의 footer를 조사해서 연결할 블록을 결정할 수 있다.
- footer는 항상 현재 블록의 시작 부분에서 한 워드 떨어진 곳에 위치한다.
- “current block”을 반환하면서 발생할 수 있는 연결 경우의 수
- B : 이전 블록 / C : 현재 블록 / A : 다음 블록 을 의미한다.
- Case 1. B와 A 모두 할당 블록이다.
- 변동 없음
- Case 2. B는 할당 블록, A는 가용 블록이다.
- C의 헤더 : C 크기 + A 크기
- A의 푸터 : C 크기 + A 크기
- Case 3. B는 가용 블록, A는 할당 블록이다.
- B의 헤더 : B 크기 + C 크기
- C의 푸터 : B 크기 + C 크기
- Case 4. B와 A 모두 가용 블록이다.
- B의 헤더 : B 크기 + A 크기
- A의 푸터 : B 크기 + A 크기

- 각 블록이 헤더와 푸터를 유지해야하므로 메모리 오버헤드가 발생할 수 있다.
- 블록 당 각각 헤더 1개, 푸터 1개 존재 : $n^2$
- 푸터를 최적화하는 방법
- 할당 블록의 푸터를 없애, 메모리를 최적화를 한다.
- 이전 블록이 가용 블록인 경우에만 이전 블록의 푸터에 있는 size 필드가 필요하다.
∴ 현재 블록의 하위 비트 중 하나에 이전 블록의 ‘allocated bit’를 저장한다.
할당 블록들은 푸터가 필요없으며 해당 공간을 데이터 공간으로 활용할 수 있다.
But, 가용 블록은 여전히 푸터가 필요하다.

Computer Systems: A Programmer's Perspective, 3rd Edition
Randal Bryant (Author), David O'Hallaron (Author)
🔗 Reference
- errno(3) - Linux manual page
(https://man7.org/linux/man-pages/man3/errno.3.html)
'🖥️ Computer Science > Computer Architecture' 카테고리의 다른 글
| Chapter 11. Network Programming (0) | 2022.12.20 |
|---|---|
| Ch1. A Tour of Computer Systems(1.7 ~ 1.9) (0) | 2022.12.06 |
| Ch1. A Tour of Computer Systems(1.1 ~ 1.6) (0) | 2022.11.03 |