
Ch1. A Tour of Computer Systems(1.1 ~ 1.6)
|2022. 11. 3. 02:56
728x90
- 프로그램 실행 이전에 어떤 일이 일어나는 가를 탐구
1-1. Information is bits + Context
- 소스 프로그램 : 비트들의 연속, 8 비트라 불리는 바이트로 구성되어 있다.

- 대부분의 컴퓨터 시스템에서는 바이트 표준으로 텍스트 문자를 표현한다.
hello.c프로그램은 일련의 byte로 저장이된다. (Figure 1.2)- 각 바이트는 일부 문자와 해당하는 정수 값을 의미한다.
- 이후
\n개행 문자에 의해 줄 바꿈이 일어난다. - ASCII 문자로 구성된 파일을 텍스트 파일이라고 한다.
- 그 외에 다른 모든 파일들은 바이너리 파일이다.
- 시스템의 모든 정보는 모두 비트 묶음으로 표시된다.
- 동일한 바이트 시퀀스더라도 정수형, 실수형, 문자열, 기계어로 나타낼 수 있다.
- 프로그램 실행시, 각 문자열을 아스키코드로 바꾸는 과정을 수행한다.
➕ C프로그래밍 언어
- 유닉스 운영 체제와 연관되어 있음
- 작고 단순한 언어 → 단순함
- 이식성이 높음
- 실용적임
1-2. Programs Are Translated by Other Programs into Different Forms
hello.c는 인간이 해석할 수 있는 고수준으로 작성되었다.- 해당 파일을 실행하려면 개별적인 C문을 저수준의 기계어 시퀀스의 다른 프로그램으로 번역해야한다.

> gcc -o hello hello.c- gcc 컴파일러 드라이버는
hello.c소스파일을 실행가능한 오브젝트 파일로 읽고 해석한다. - 번역은 Figure 1.3 과 같은 순서로 수행된다.
- 컴파일 시스템
- 전처리기
- 컴파일러
- 어셈블러
- 링커
- 전처리 단계(Processing phase)
- 본래의 C 프로그램을
전처리기 지시자(#)에 따라 수정한다. - →
hello.i
- 본래의 C 프로그램을
- 컴파일 단계(Compilation phase)
- 컴파일러는 어셈블리어로 프로그램이 저장된다.
- 어셈블리어 : 기계어와 일대일 대응이 되는 컴퓨터 프로그래밍의 저급 언어
- →
hello.s
- 어셈블리 단계(Assembly phase)
- 어셈블러가
hello.s를 기계어로 번역하고 이를 재배치가 가능한 오브젝트 목적 프로그램(relocatable object program)형태로 묶음 - main 함수의 명령어들을 인코딩하기 위한 17바이트를 포함하는 바이너리 파일
- →
hello.o
- 어셈블러가
➕ 오브젝트 파일 (바이터리 코드와 데이터를 가짐)
- 재배치 가능한 오브젝트 파일(Relocatable object file)
- 컴파일 시에 다른 재배치 가능한 오브젝트 파일들과 결합이 가능
- 실행가능한 오브젝트 파일(Executable object file)
- 메모리로 직접 로드되어 실행이 가능
- 공유 오브젝트 파일(Shared object file)
- 로드 타임이나 런타임때 동적으로 메모리로 로드되고 링킹이 가능
- 링크 단계(Linking phase)이후,
hello파일은 실행가능한 목적파일로 메모리에 적재되어 시스템에 의해 실행된다.- 만약
hello.c파일에서 printf 함수를 호출한다면printf.o목적파일과hello.o목적파일을 결합해야만 사용을 할 수 있다. 이때, 링커가 이 작업을 수행한다.
- 만약
- GNU environment
- GNU/리눅스는 유닉스(Unix) 운영체제를 모델로 만든 운영체제
- EMACS editor
- GCC compiler
- GDB debugger
- assembler
- linker
- utilities for manipulating binaries
- GNU/리눅스는 유닉스(Unix) 운영체제를 모델로 만든 운영체제
1-3. It Pays to Understand How Compilation Systems Work
- 컴파일 시스템 이해의 중요성
- Optimizing program performance
- Understanding link-time errors
- Avoiding security holes
1-4. Processors Read and Interpret Instructions Stored in Memory
- 쉘은 커맨드라인 인터프리터로 프롬프트를 출력하고 명령어 라인을 입력 받아 그 명령을 실행한다.
💡 만약 명령어 라인이 내장 쉘 명령어가 아니면 실행파일의 이름 으로 판단하고 파일을 로딩 및 실행
1.4.1 Hardware Organization of a System
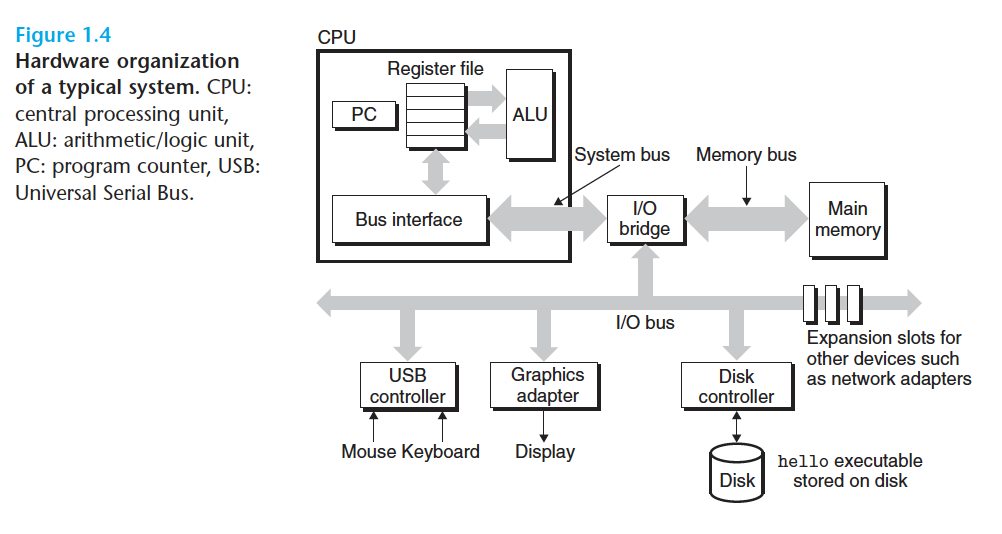
Buses
- 시스템 내부를 관통하는 전기적 도관
- 컴포넌트간의 바이트 정보를 전송한다.
- word
- 데이터 전송의 고정 크기의 바이트 단위
- 한 개의 워드를 구성하는 바이트 수는 시스템 마다 보유하는 기본 시스템 변수
- ex. 32bit 시스템 → 4byte, 64bit 시스템 → 8byte
I/O Devices
- 시스템과 외부 세계와의 연결 담당
- 각 입출력 장치는 컨트롤러나 어댑터에 의해 입출력 버스와 연결된다.
- 컨트롤러 : 칩셋이나 시스템의 인쇄 기판(머더 보드)에 장착된다.
- 어댑터 : 머더보드의 슬롯에 장착되는 카드
- ex. 입력용 키보드 & 마우스, 출력용 디스플레이, 디스크 드라이브
Main Memory
- 프로세서가 프로그램을 실행하는 동안 데이터와 프로그램을 모두 저장하는 임시 저장장치
- 물리적 메모리 : DRAM칩들로 구성
- 논리적 메모리 : 연속적인 바이트 배열로, 고유의 주소(배열의 인덱스)를 가지고 있다.
Processor
- 중앙처리장치(CPU)
- 메인 메모리에 저장된 명령어를 해석(실행)하는 엔진
- 프로세서의 중심에는 프로그램 카운터(PC)가 있다.
💡 프로그램 카운터(Program Counter, PC) (= 명령어 포인터)
- CPU 내부에 있는 레지스터 중 하나로서, 다음에 실행될 명령어의 주소를 가지고 있다.
- 프로세서는 명령어 실행 모델(ISA)을 따라 작동한다.
- ISA에서 명령어들은 아래와 같은 규칙적인 순서로 실행된다.
- 프로세서는 PC가 가리키는 메모리로부터 명령어를 읽어온다.
- 이 명령어에서 비트들을 해석해서 명령어가 의미하는 동작을 수행한다.
- PC를 다음 명령어 위치로 업데이트한다.
💡 ISA(Instruction Set Architecture)
- 명령어 집합 구조
- 최하위 레벨의 프로그래밍 인터페이스
이러한 동작들은 메인 메모리, 레지스터 파일, 수식/논리 처리기(ALU) 를 순환하며 처리된다.
- Load : 메인 메모리 → 레지스터
- Store : 레지스터 → 메인 메모리
- Operate : 두 레지스터 값을 복사하여 수식연산 수행 후, 레지스터에 저장
- Jump : 명령어 자신으로 부터 한 개의 워드를 추출하여 PC에 저장
⭐ 이때 각 데이터들은 이전 값에 덮어쓰는 방식으로 작동한다.
1.4.2 Running the hello Program

1. 쉘 프로그램 상에 ./hello 입력
2. 각 문자 h, e, l , l, o 를 읽어 들여서 메모리에 저장

3. 엔터를 눌러 명령의 종료를 알림
4. 셸 프로그램은 실행파일에서 코드와 데이터를 복사해서 이를 디스크에서 메인 메모리로 적재한다.

5. 복사한 코드의 main 루틴을 실행한다.
6. 이때 인스트럭션을 해석해서 나온 hello world\n 를 디스플레이에 출력한다.
1-5. Caches Matter
- 기계어 인스트럭션의 수행 과정 : 하드디스크 → 메인 메모리 → 프로세서(반복적인 복사 발생)
- 이때 오버헤드가 많이 발생한다.
- 물리학의 법칙으로 인해 더 큰 저장장치는 작은 저장장치보다 느린 속도를 갖는다.
- Ex.
- 크기 : 디스크 드라이버 > 메인 메모리 - 약 1,000배
- (데이터를 읽어들이는) 속도 : 프로세서 → 디스크 > 프로세서 → 메인 메모리 - 약 1,000만배
이러한 프로세서 ↔ 메모리 간 격차에 대응하기 위해 캐시 메모리가 등장했다.
- 속도가 빠른 장치와 느린 장치 간의 속도차에 따른 병목 현상 방지
캐시 메모리(Cache Memory)

- 프로세서가 단기간에 필요로 할 가능성이 높은 정보를 임시로 저장할 목적으로 사용
- 중간 버퍼 역할을 하는 CPU내 또는 외에 존재하는 메모리
- 캐시는 최적화 알고리즘을 사용하여 데이터 처리속도를 높인다.
- L1, L2, L3와 같은 다중 캐시 메모리를 사용하여 Cache Hit을 극대화 한다.
- 이때의 ‘L’은 Level의 약자이다. (1차, 2차, 3차)
- ex. L1에서 데이터를 찾고 만약 L1에 없다면 L2로 수준을 높여가며 찾는다.
- 캐시는 지역성(Locality)을 이용하여 시스템이 매우 크고 빠른 메모리 효과를 얻을 수 있다.
- 공간 지역성 : 최근에 사용했던 데이터와 인접한 데이터가 참조될 가능성이 높다는 특성
- 시간 지역성 : 최근에 사용했던 데이터가 재참조 될 가능성이 높다는 특성
💡 Cache Hit : CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있을 경우
1.6 Storage Devices Form a Hierarchy
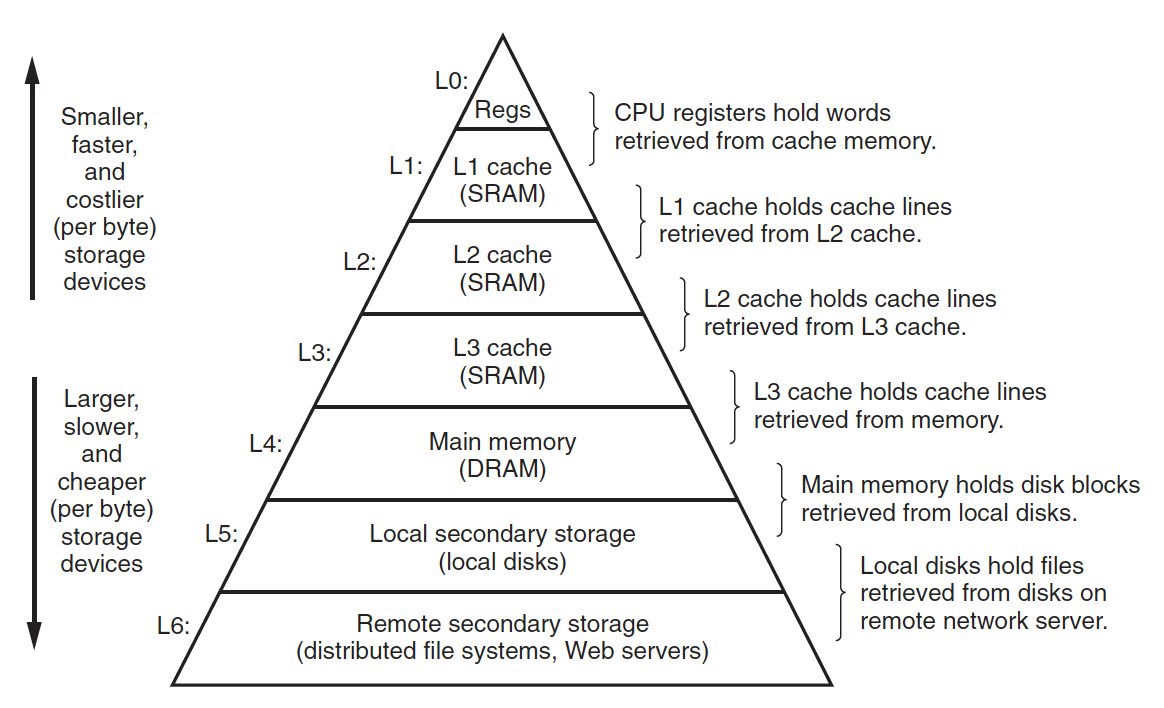
- 모든 컴퓨터 시스템의 저장장치들은 메모리 계층 구조로 구성되어 있다.
- 계층의 꼭대기에서부터 맨 밑바닥까지 이동할 수록 저장장치는 더 느리고, 더 크고, 가격이 싸진다.

Computer Systems: A Programmer's Perspective, 3rd Edition
Randal Bryant (Author), David O'Hallaron (Author)
🔗 Reference
- 1.2. GNU/리눅스란?
- 어셈블리어
- 오브젝트 파일들
- 프로그램 카운터
- 명령어 집합
- [운영체제(OS)] 10. 캐시 메모리(Cache Memory)
- Ch5-4. 캐시(Cache memory)
728x90
'🖥️ Computer Science > Computer Architecture' 카테고리의 다른 글
| Chapter 11. Network Programming (0) | 2022.12.20 |
|---|---|
| Ch9. Dynamic Memory Allocation(9.9) (1) | 2022.12.06 |
| Ch1. A Tour of Computer Systems(1.7 ~ 1.9) (0) | 2022.12.06 |