
728x90

KMP : 크누스 - 모리스 - 프랫 어쩌구.
- 이전 단계에서 검사했던 결과를 버리지 않고 효율적으로 활용하는 알고리즘
- 검사했던 결과를 버리지 않고 효율적으로 활용하는 알고리즘
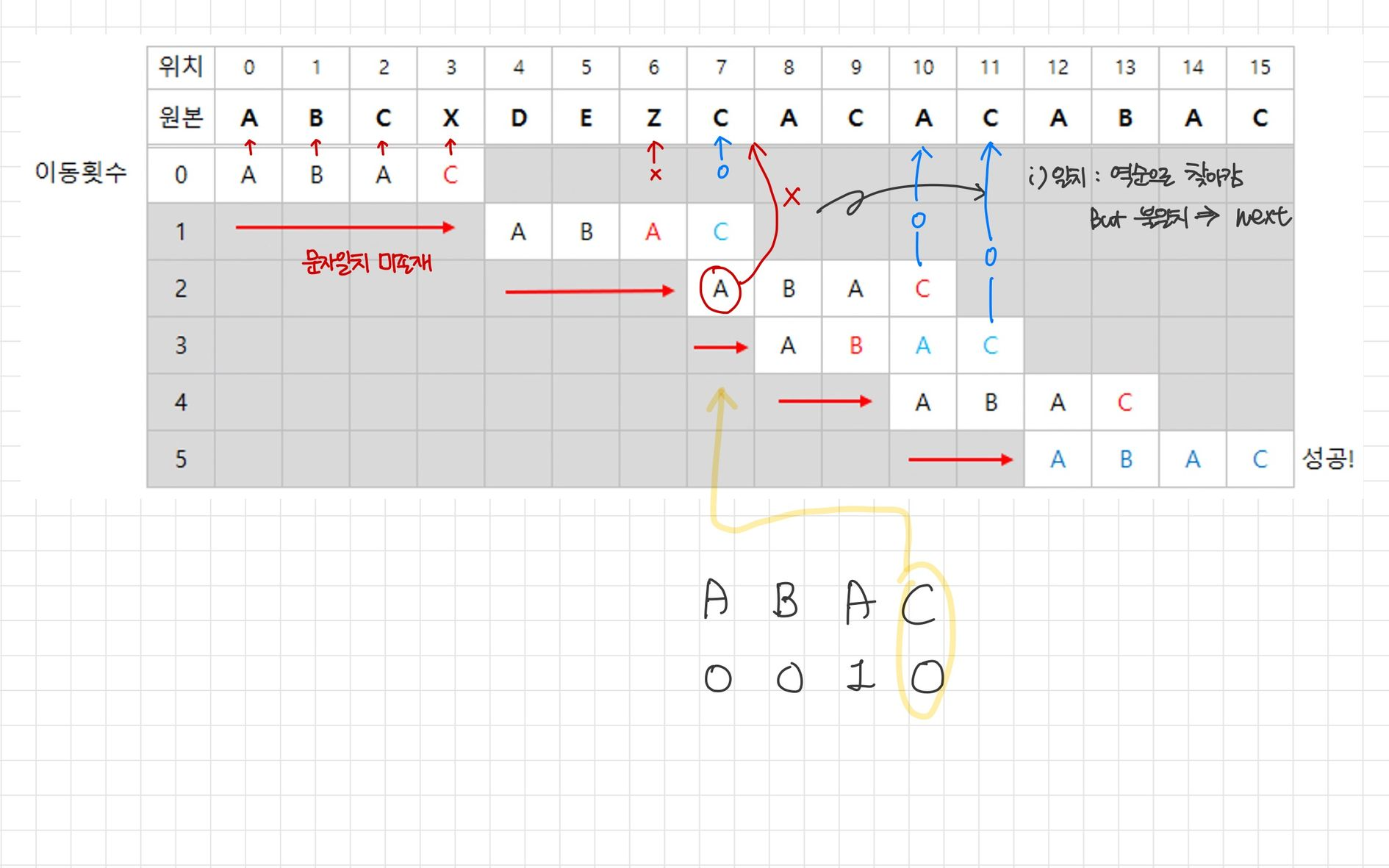
- 불일치가 발생하기 직전까지 같았던 부분은 다시 비교하지 않고 패턴 매칭을 진행
- 비교 횟수를 줄여, 검색 알고리즘의 효율성을 높임
- 검사 부분 내에 패턴의 일부와 동일한 부분이 있는지 판단
- 그 위치만큼 밀기
- 텍스트와 패턴 안에서 겹치는 문자열을 찾아내 검사를 다시 시작할 위치를 구해, 패턴의 이동을 최대한 크게 한다.
- KMP 테이블 생성
- 패턴과 패턴을 서로 겹치도록 맞추고 검사를 시작할 곳을 테이블에 작성한다.
- 미리 나온 패턴에 대해 겹치는 부분이 있는 지 검사한다.
- KMP 법에서 사용하는 패턴 문자열 만들기
- 접두사 배열과 접미사 배열을 만든다.
- 대상 문자열과 타겟 문자열을 처음에 둔다.
- 대상 문자열의 접두부 배열과 접미부 배열을 추출한다.
- 두 배열을 비교했을 때 같은 부분을 찾는 데, 가장 긴 문자열을 추출한다.
- 이후 추출한 접미부의 겹치는 부분의 시작 인덱스로 이동하고 다음 탐색은 이 위치에서 시작을 한다.
🏃🏻 Try
🤔 같은 문자가 접두사와 접미사에 몇 개가 있는가?
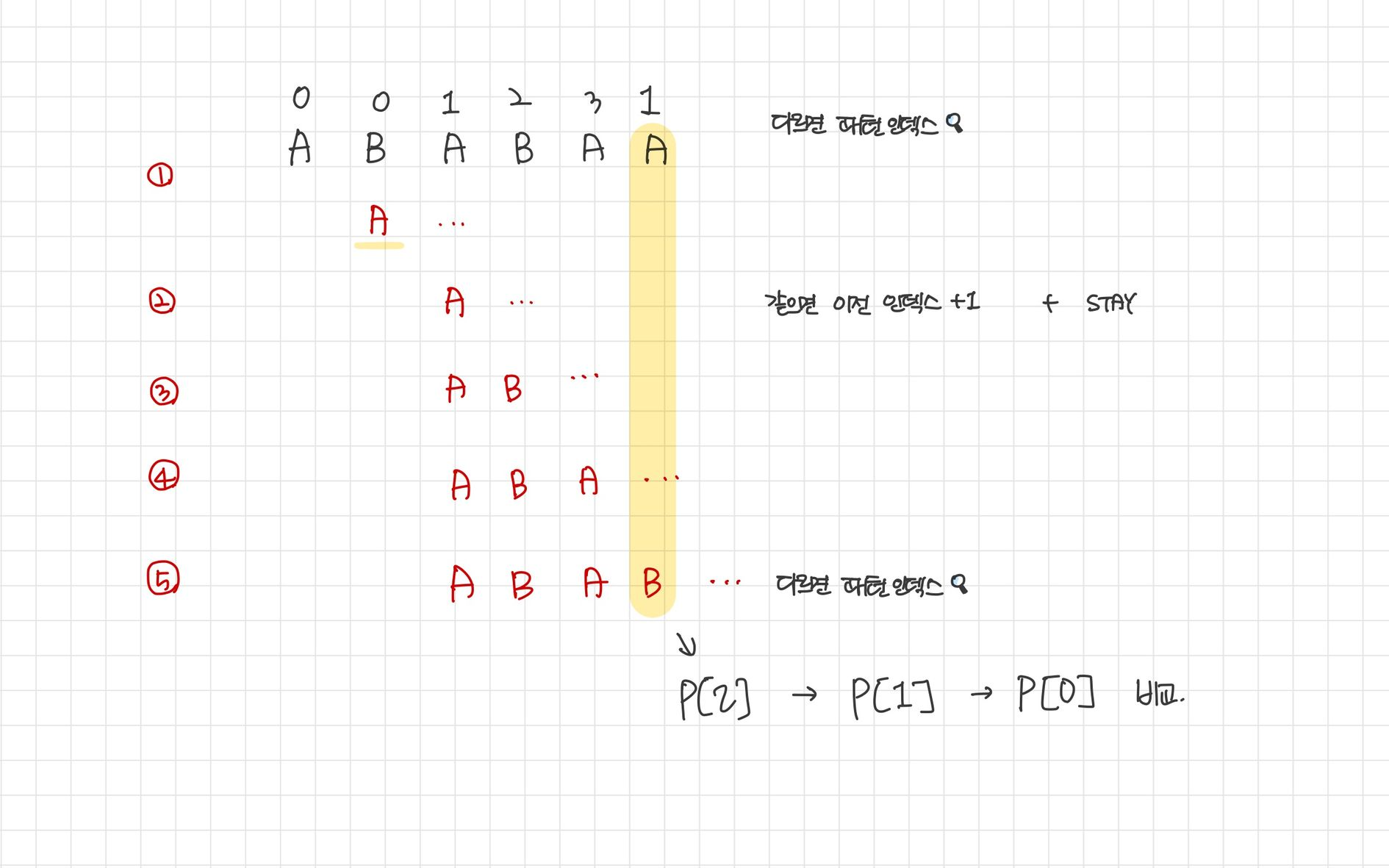
- 실패 함수를 만든다! (= $COMPUTE-PREFIX-FUNCTION$ = 패턴 문자열 )
- 실패 했을 때 얼마나 점프할 수 있는가?
논리적 접근
- 접두사와 접미사의 최대 일치 길이를 구한다.
- “접두사와 접미사가 같으면 그만큼을 점프할 수 있다” 의 IDEA
구현
i는 접미 문자,j는 접두 문자로 가정i는 계속 증가j는 문자가 같을 경우에만 증가
- 불일치가 발생하면 역순으로 부분 일치 문자열 추적
AOB.
1️⃣ 가끔 알고리즘 서적을 보면 부분 문자열이 -1 로 시작하는 경우가 있는데, KMP를 더욱 이해하기 난해하게 만드는 원흉 중 하나.
🔗 Reference

728x90