
728x90
해당 포스팅은 'Cracking the Coding Interview'를 읽으며 정리한 내용을 담은 포스팅으로 이론 내용 및 모든 문제의 출처는 'Cracking the Coding Interview'에 있습니다.
문제 자체에 대한 설명은 담고 있지 않으며 원문 파일은 GitHub 및 원문 책 사이트를 통해 다운로드하실 수 있습니다.
1. An Analogy
- 디스크에 있는 파일을 다른 지역에 살고 있는 친구에게 가능한 빨리 보내려고 한다고 가정해보자.
대부분의 사람들은 문제를 듣자마자 온라인 의 방식을 생각하곤 한다.
But, 경우에 따라 맞을 수도 틀릴 수도 있다.
- 파일의 크기가 작다면 당연히 온라인을 통한 전송이 빠를 것이다.
- 그러나 파일의 크기가 아주 크다면 비행기를 통해 물리적으로 배달하는 게 더 빠를 수도 있다.
- 실제로 1TB 크기의 파일을 온라인을 통해 전송하려 한다면 하루 이상 걸릴 수도 있다.
2. Time Complexity
- 점근적 실행 시간(asymptoticc runtime)
- big-O
- 온라인 전송
- $O(s)$
- 여기서 s는 파일의 크기가 된다.
- 파일의 크기가 증가함에 따라 전송 시간 또한 선형적으로 증가한다.
- 비행기를 통한 전송
- 파일 크기에 관계없이 $O(1)$
- 파일의 크기가 증가한다고 해서 친구에게 파일을 전송하는 데 걸리는 시간이 늘어나지 않는다.
- ∴ 상수 시간 만큼 소요된다.
- 상수가 얼마나 큰지 or 선형식이 얼마나 천천히 증가하는지에 관계없이 숫자가 커지다 보면 선형식은 언젠가 상수를 뛰어넘게 된다.

- 그 밖의 다양한 실행 시간
- O(log N)
- O(N log N)
- O(N)
- O(N^2)
- O(2^N)
2-1. big-O, big-θ, big-Ω
- 학계에서 수행 시간을 표기할 때 사용하는 개념
- O(big-O)
- 시간의 상한
- 시간의 상한이므로 배열의 모든 값을 출력하는 알고리즘 $O(N)$ 에 대해 $O(N^2)$, $O(N^3)$ 으로 표현할 수 있다.
- 근데 굳이 이런식으로 표현할 필요는 없음 ➡️ 개념 상으로만 이해하자!
- Ω(big-Omega)
- 등가 개념 혹은 하한
- 배열의 모든 값 출력 알고리즘
- $Ω(N)$ , $Ω(logN)$ , $Ω(N)$ 으로 표현 가능
- 어떤 알고리즘으로 표현하느냐에 따라 달라질 수 있음을 나타냄
- ∴ Ω 수행 시간보다 빠를 수 없다!
- θ(big-theta)
- O와 Ω 둘 다 의미
- 어떤 알고리즘의 수행 시간이 $O(N)$ 이면서 $Ω(N)$ 이라면 $θ(N)$ 이다.
💡 인터뷰에서는 big-O의 의미는 θ의 의미와 가까우므로 big-O에 대해 언제나 딱 맞게 표기하자.
2-2. 최선의 경우, 최악의 경우, 평균적인 경우
- 알고리즘의 수행 시간을 세 가지 다른 방법으로 나타낼 수 있다.
- e.g. 퀵 정렬
- '축'이 되는 원소 하나를 무작위로 뽑은 뒤, 이보다 작은 원소들은 앞에, 큰 원소들은 뒤에 놓이도록 원소의 위치를 바꾼다.
- '부분 정렬(partitial sort)' ➡️ 왼쪽, 오른쪽을 재귀적으로 정렬해감
- 최선의 경우
- 모든 원소 동일 : 단순히 배열 한 차례 순회
- $O(N)$
- 최악의 경우
- 가장 큰 원소가 계속해서 축이 됨
- 고작 하나 줄어든 크기의 부분 배열로 나눔
- $O(N^2)$
- 평균적인 경우
- 최선과 최악의 경우가 가끔 발생
- $O(N logN)$
- 최선의 경우는 아무 알고리즘 + 특수한 조합을 통해 어떻게든 $O(1)$로 구현 가능
- ∴ 딱히 논의 대상이 아님!
- 대부분의 경우 최악의 경우와 평균적인 경우가 같다.
- 최선/최악/평균의 경우 ≠ big-O/θ/Ω
- 아무런 관련성 없음
최선/최악/평균의 경우: 어떤 입력 또는 상황에서 big-O로 표현big-O/θ/Ω: 각각 상한, 하한, 딱 맞는 수행 시간을 의미
3. Space Complexity
- 알고리즘에서는 시간뿐 아니라 메모리 또한 신경 써야 한다.
- ⭐️재귀 호출에서 사용하는 스택 공간 또한 공간 복잡도에 포함된다.
int sum(int n) {
if (n <= 0) {
return 0;
}
return n + sum(n - 1);
}해당 코드는 호출될 때마다 스택의 깊이가 깊어진다.

전부 호출 스택에 더해지고 실제 메모리 공간을 잡아 먹는다.
But, 단지 n번 호출했다고 해서 $O(n)$ 공간을 사용하진 않는다.
int pairSumSequence(int n){
int sum = 0;
for (int i = 0; i < n; i++){
sum += pairSum(i, i + 1);
}
return sum;
}
int pairSum(int a, int b) {
return a + b;
}- 함수들이 호출 스택에 동시에 존재하지 않으므로 O(1) 공간만 사용한다.
4. Drop the Constants
- big-O는 단순히 증가하는 비율을 나타내는 개념
- 특수 입력에 한해, O(N)이 O(1)보다 빠르게 동작할 수 있음!
- ∴ 수행 시간에서 상수항을 무시한다!
- "수행 시간이 어떻게 변화하는 지를 표현해주는 도구"이므로 복잡한 연산을 분석하거나 세부사항을 고려할 필요는 없다.
- $O(n)$ 이 언제나 $O(2N)$ 보다 나은 것은 아니라는 사실만 알고 있자.
5. Drop the Non-Dominant Terms
- $O(N^2 + N)$ 에서 두 번째 N은 특별히 중요한 항이 아니다.
- ∴ 수식에서 지배적이지 않은 항은 무시해도 된다.
- big-O 시간 증가율 그래프
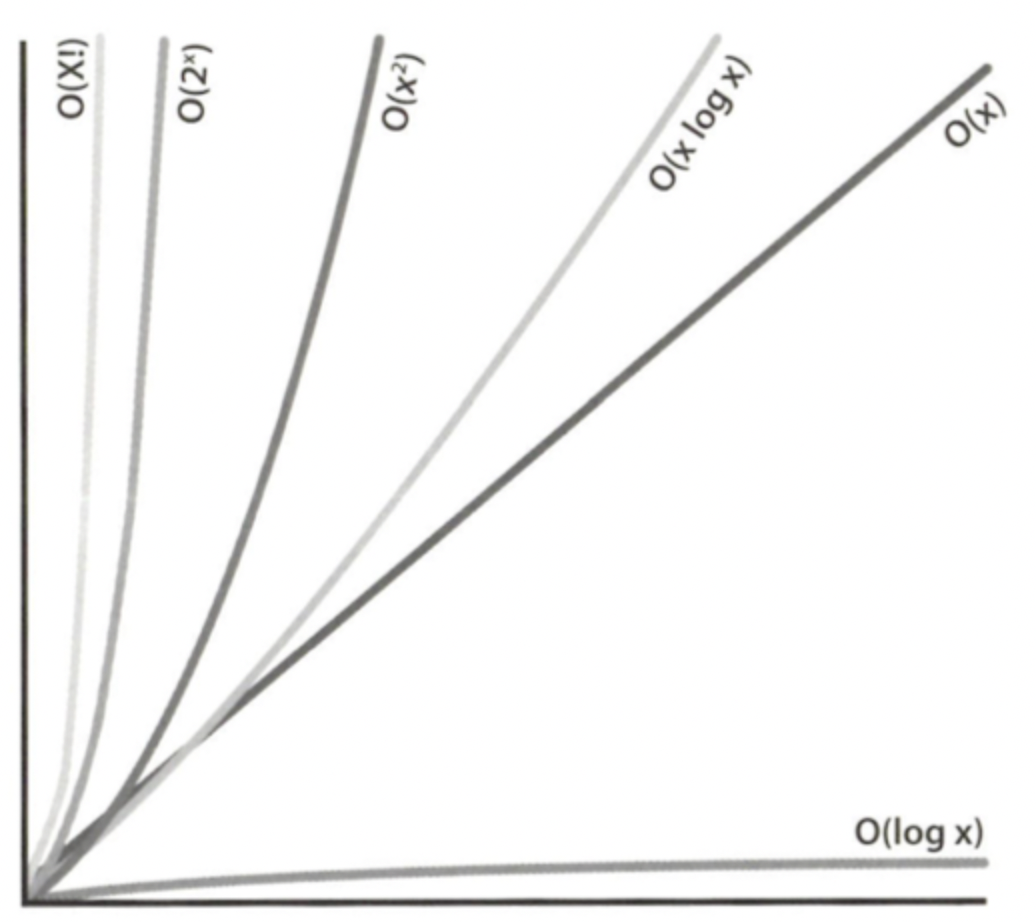
6. Multi-Part Algorithms: Add vs. Multiply
- 덧셈 수행 시간의 경우
for (int a : arrA) {
print(a);
}
for (int b : arrB) {
print(b);
}
- 곱셈 수행 시간의 경우
for (int a : arrA) {
for (int b : arrB) {
print(a + "," + b);
}
}
- A + B : "A 일을 모두 끝마친 후에 B 일을 수행하라"
- A * B : "A 일을 할 때마다 B 일을 수행하라"
7. Amortized Time
- ArrayList (동적 가변 크기 배열)
- 배열의 역할을 함과 동시에 크기가 자유롭게 조절되는 자료구조
- 원소 삽입 시 필요에 따라 배열의 크기를 증가시킬 수 있으므로 ArrayList의 공간이 바닥날 일 X
- 배열의 용량이 꽉 찼을 때, ArrayList 클래스는 기존보다 크기가 두 배 더 큰 배열을 만든 뒤에 이전 배열의 모든 원소를 새 배열로 복사한다.
- 이때 삽입 연산 시간 : $O(N)$
- ∵ 기존의 모든 원소를 새 배열로 복사해야하기 때문
- But, 대다수의 경우에는 배열에 가용 공간이 존재하고 이때의 삽입 연산은 $O(1)$이 소요된다.
이러한 두 가지의 연산 ("배열이 꽉 찼을 때 삽입", "일반적인 삽입")을 포함한 전체 수행 시간을 따진다.
- 분할 상환 : 최악의 경우는 가끔 발생하지만 한 번 발생하면 그 후로 꽤 오랫동안 나타나지 않음
- ∴ 이러한 경우의 상환 시간은 $O(1)$ 이다.
8. Log N Runtimes
- 이진 탐색
- N개의 정렬된 원소가 들어 있는 배열에서 원소 x를 찾을 때 사용
- 원소 x와 배열의 중간값을 비교 후 같으면 반환
- x < 중간값의 경우, 왼쪽 탐색
- x > 중간값의 경우, 오른쪽 탐색
- 처음에는 원소 N개가 들어있는 배열에서 시작
- 한 단계 이후, 탐색해야할 원소의 개수가 $N/2$로 줄어듦
- 두 단계 이후, 탐색해야할 원소의 개수가 $N/4$로 줄어듦
- ∴ 따라서 총 수행 시간은 몇 단계 만에 1이 되는지에 따라 결정된다.
$2^k = N$ 를 만족하는 $k$ 값 도출 ➡️ 로그(log)를 사용하여 표현
- 어떤 문제에서 원소의 개수가 절반씩 줄어든다면 그 문제의 수행 시간은 $O(log N)$이 될 가능성이 크다.
- 균형 이진 탐색 트리에서도 매 단계마다 원소의 대소 비교 후 좌우로 내려가므로 이때도 $O(log N)$의 수행 시간이 소요된다.
- 🤔 그렇다면 big-O에서 로그의 밑은?
- 고려할 필요 X (수학적인 개념)

- 💡 밑이 다른 로그는 상수항 만큼 차이가 나므로 big-O 표현식에서는 대부분 로그의 밑은 무시한다.
9. Recursive Runtimes
- 피보나치 수열 코드
int f(int n) {
if (n <= 1) {
return 1;
}
return f(n - 1) + f(n - 1);
}

- 전체 노드의 개수 : $2^0 + 2^1 + 2^2 + 2^3 + ... + 2^N (= 2^{N+1} - 1)$
- ∴ 재귀 함수에서 수행 시간
- $O(분기^{깊이})$
- 공간 복잡도 : $O(N)$
- 특정 시각에 사용하는 공간의 크기는 $O(N)$ 이다.
- 전체 노드의 개수 : $O(2^N)$
728x90
'🖥️ Computer Science > Cracking the Coding Interview' 카테고리의 다른 글
| Linked Lists (0) | 2023.06.29 |
|---|---|
| Arrays and Strings (0) | 2023.06.28 |