
AlexNet → VGG → IncepctionNet → ResNet(인간을 뛰어넘는 최초의 인공신경망 모델)
CNN(Convolution Neural Network)
- 구조 자체는 DNN과 유사
- 레이어 강화, GPU 사용하여 보완
- Hidden Layer 에서 특징 추출, 분류 분석이 이루어질 때
└ 특징 추출은 각 이미지 데이터에서 지엽적인 특징을 추출하는 과정이 추가됨
기존 모델들은 특징 추출과 분류 분석 둘다 이미지 전체에 대해 분석이 이루어지는데, CNN의 경우 특징 추출은 이미지의 지엽적인 특징만 추출하여 분석 진행
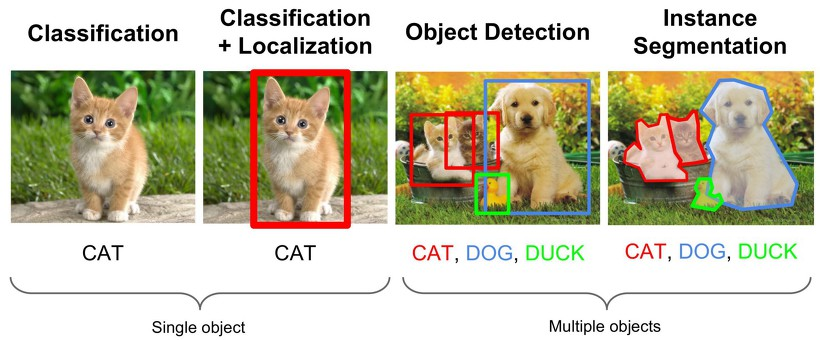
- Single Object
a. Classification:
b. Classification + Localization(Bounding Box)
- Multiple Object
a. Object Detection
b. Instance Segmentation
Hidden Layer 구성

특징 추출 계층(Feature Extraction)
- 각 위치정보에 대한 특징 추출 → 분석
- 특징을 위치정보와 함께 추출
- FCL로 이루어진 일종의 MLP.
<레이어 구성>
- ⭐ Convolution
- activation function : Relu
- Pooling : 데이터 사이즈 축소를 위한 Sub Sampling
💡 이미지 데이터의 경우 여러개의 픽셀 단위로 같이 분석해야 더욱 정확도를 가짐
(인접 픽셀의 경우 이미지 특징이 비슷하므로)
온도, 자연어처리의 경우에도 비슷한 원리이다!
분류 분석 계층(Classification)
- DNN모델을 그냥 붙였다고 생각
<레이어 구성>
- Flatten
└ 특징 정보 + 위치 정보(3D) : 3Dimension Tensor는 MLP(분류 분석 계층)에 넣을 수 없음
→ 따라서, 1Dimension Tensor로 Flatten 진행
- FCL(Fully Connected Layer)
- Softmax
Image Matrix Representation
- 흑백 이미지
: 0부터 255사이의 범위 값을 갖는 1Dimension Tensor로 표현
(0(white) - 255(black))
- 컬러 이미지
: RGB 3개의 채널로 표현한 3Dimension Tensor로 표현
Filter, Convolution, Featuremap
- Filter적용(Convolution 연산) → Feature Map생성
Filter (= kernel, mask)
- 입력된 이미지의 특성 추출을 위한 도구
- 일반적으로 정사각 행렬로 정의
- 슬라이딩으로 필터를 훑으면 수평선 정보, 수직선 정보 detection
└ 이미지에 Filter를 Convolution연산을 적용하여 패턴 추출
- CNN은 이러한 구조를 그대로 차용하여 직접 분석을 시키고 분류 분석 모델에 넣어 학습을 통해 찾아내고자 한다.
Filter : 가중치들을 담고 있는 행렬
└ CNN 과정 자체가 이 Filter를 조정해나가는 과정이라고 보면된다.
Feature Map
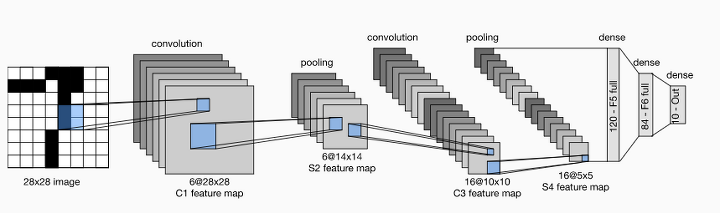
- 결과값이 기존 모델에서는 하나의 Scalar값으로 표현됐다면 Feature Map은 이러한 Scalar값이 모여있는 Matrix 형태로 표현된 것이다.
- filter를 이미지의 부분부분마다 적용시키며 전체 이미지내에 어느 정도 강도로 들어있는지를 나타내는 Feature Map을 도출할 수 있다.
Convolution
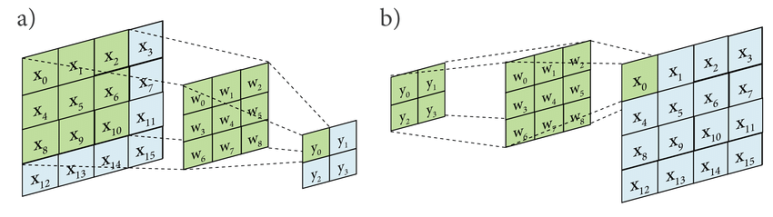
- 두 개의 matrix를 동일한 position 값 끼리 곱한 후 더하는 연산
FC Layer 🆚 Conv Layer
- 이미지 분석에서의 Conv Layer와 FC Layer
Conv Layer
: 고정 사이즈의 필터가 input 영역 필터의 사이즈만큼 sliding 하면서 분석
FC Layer
: input 이미지 전체 픽셀에 연결되어 있는 퍼셉트론의 가중치를 이용하여 한번에 분석
└ 하나의 퍼셉트론은 특정 위치에 존재하는 특성만 검출할 수 있다.
Conv Layer의 특성
- Translation invariance
: 함수의 입력이 바뀌어도 출력은 그대로 유지 (위치 정보가 바뀌어도 동일한 이미지를 찾아낼 수 있음)
- Locality of pixel dependencies
: 이미지에서 특징들은 좁은 영역에 여러 픽셀에 거쳐서 나타난다.
└ 하나 또는 전체 픽셀을 분석할 필요 없이, 3x3 또는 5x5와 같은 작은 사이즈의 픽셀 묶음으로 분석시 주요 특성 추출 가능
+) Stride, Padding, Pooling
Stride
Locality of pixel dependencies → 입력 이미지의 근접한 영역에 필터 적용시, 유사한 결과 도출
→ 비효율 발생(인근 위치에 비슷한 값 반복 도출로 인한 비효율)
∴ 간격을 지정해주어 해결
└ 이때의 간격 : Stride
Padding
- Conv Layer를 거치면 Feature Map의 사이즈는 원본 사이즈보다 작아진다.
- 이때 연산에서는 행렬의 사이즈가 중요한데, shape이 맞지않으면 연산 불가로 인한 정보 누락이 발생
∴ Padding 기법으로 원본 행렬과 크기를 맞춰줌으로써 해결
└ 이때 크기를 맞춰주는 작업 : Padding

- Zero Padding
- Same Padding
Pooling
- Feature Map에서 크기를 축소(Sub Sampling)하여 Locality of pixel dependencies 로 인한 비효율 방지
- 작업과 유사
- 고해상도 이미지 → 저해상도 이미지
- 일반적으로 Max 값으로 값을 채워넣는 Max Pooling과 Average 값으로 값을 채워넣는 Average Pooling 이 주로 사용된다.

💡 분류 분석 모델에서는 주로 Max Pooling이 사용된다.
- Max Pooling 시, 원본 이미지의 주요 특성 극대화
- Average Pooling 시, 원본 이미지의 주요 특성이 소실될 우려 발생(이미지가 흐려짐)
Tensorflow CNN API
tf.keras.layers.Conv2D
tf.keras.layers.Conv2D | TensorFlow Core v2.6.0
2D convolution layer (e.g. spatial convolution over images).
www.tensorflow.org
tf.keras.layers.MaxPool2D
tf.keras.layers.MaxPool2D | TensorFlow Core v2.6.0
Max pooling operation for 2D spatial data.
www.tensorflow.org
'🤖 AI' 카테고리의 다른 글
| [DNN] 신경망의 구조 (0) | 2022.02.07 |
|---|---|
| [DNN] 그래디언트, 옵티마이저 정리 (0) | 2021.10.02 |
| [Tensorflow_Keras_API] tf.keras.utils.get_file : 데이터 다운로드 메서드 (0) | 2021.07.21 |
| [Jupyter Notebook] 매직 키워드(매직 커맨드 '%') (0) | 2021.07.05 |
| [Tensorflow] 텐서플로우 자료형 (0) | 2021.07.05 |